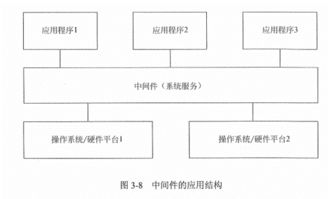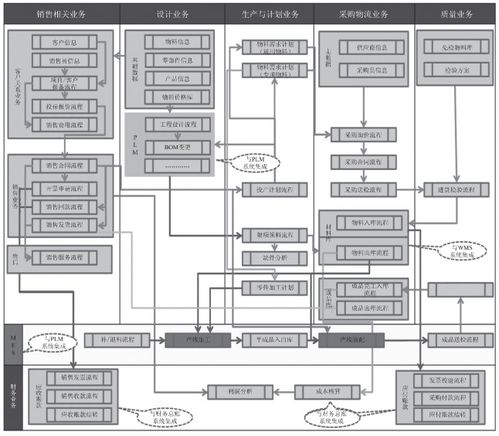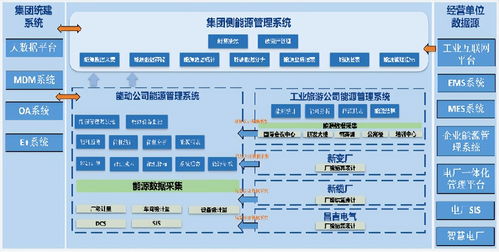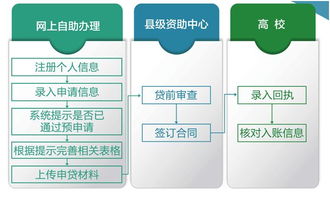
洪澤地區傳來令人振奮的消息,貧困家庭可以申請每年近8000元的助學補貼,為孩子們的教育之路提供堅實保障。這項政策通過信息系統集成服務實現高效、透明的申請流程,確保資助精準到位。
助學補貼面向洪澤地區的貧困家庭,覆蓋從小學到大學的各個教育階段。符合條件的家庭可以通過在線系統提交申請,系統會自動審核信息并快速反饋結果。信息系統集成服務不僅簡化了申請步驟,還減少了人為錯誤,使資源分配更加公平公正。
此舉旨在減輕貧困家庭的經濟負擔,促進教育公平,為下一代創造更多機會。申請者需提供相關證明材料,并在規定時間內完成提交。洪澤政府呼吁所有符合條件的家庭積極參與,不要讓經濟困難成為孩子求學的障礙。
這不僅是經濟支持,更是社會關愛的體現,期待更多孩子能因此受益,實現人生夢想。